
Overview of Statistical Machine Learning 💻
MSSC 6250 Statistical Machine Learning
Image/Object Recognition









Recommender System

COVID Detection

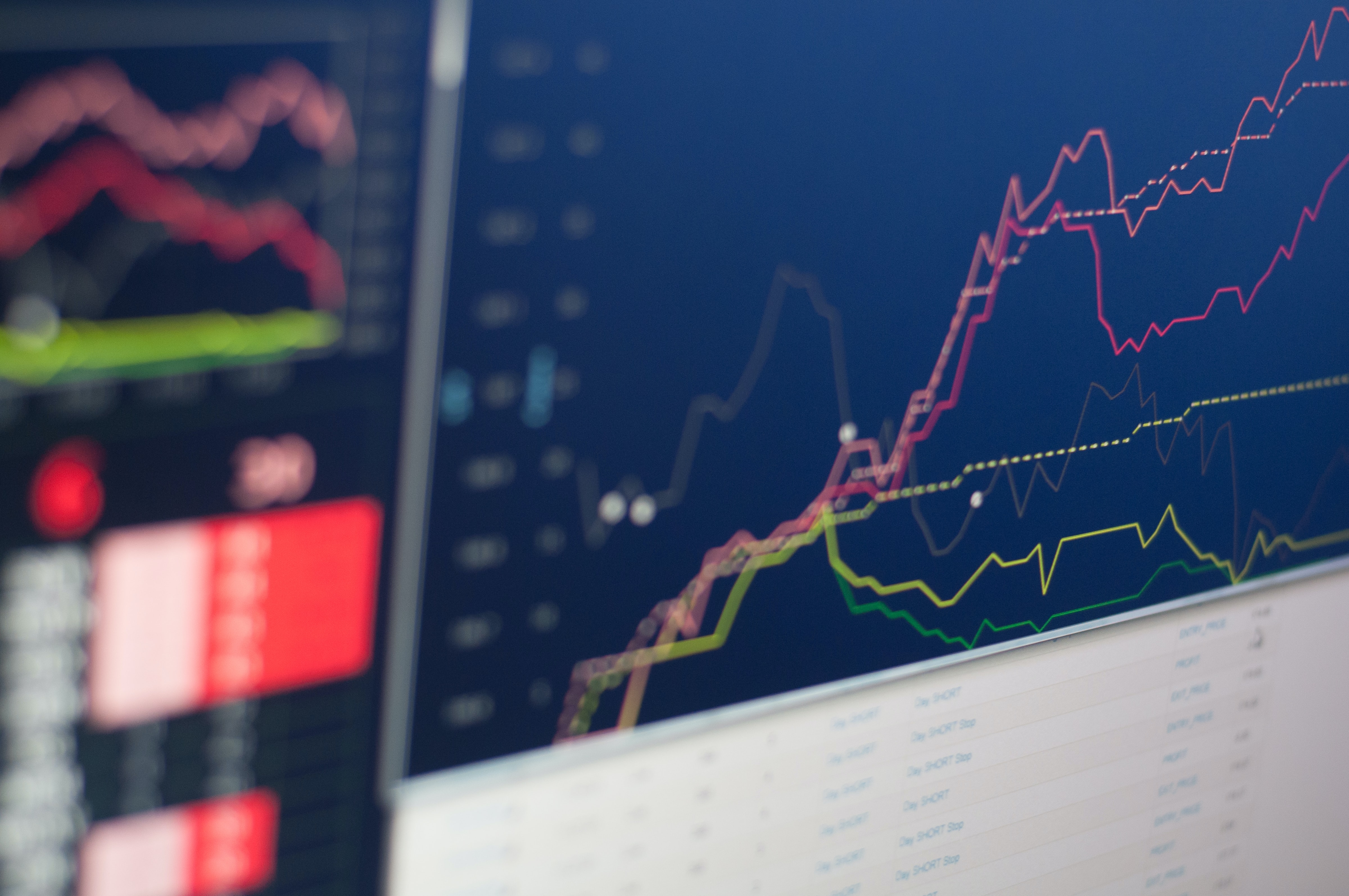
Stock Price Forecasting
Fancy Terms and Larger Grant!
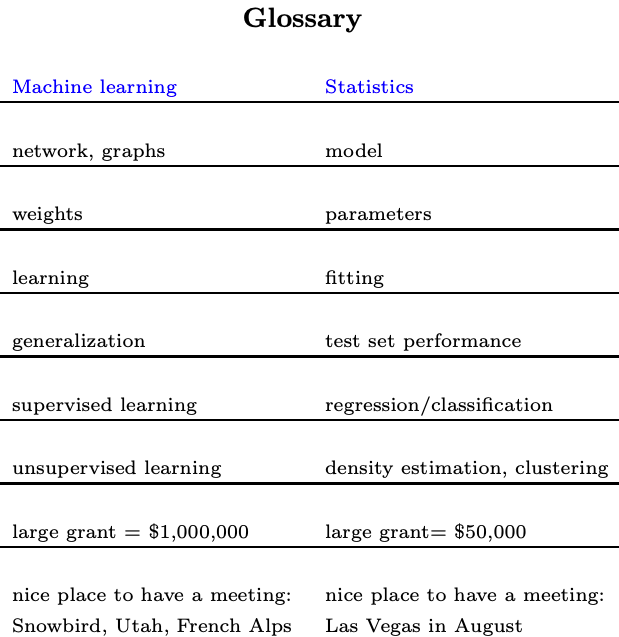
Source: http://statweb.stanford.edu/~tibs/stat315a/glossary.pdf
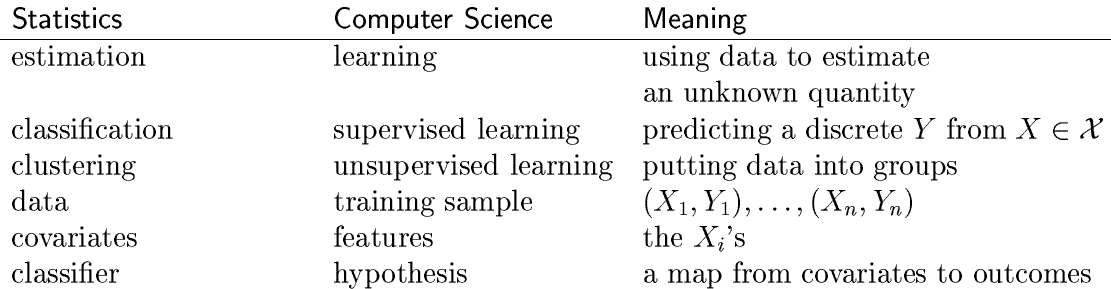
Source: All of Statistics
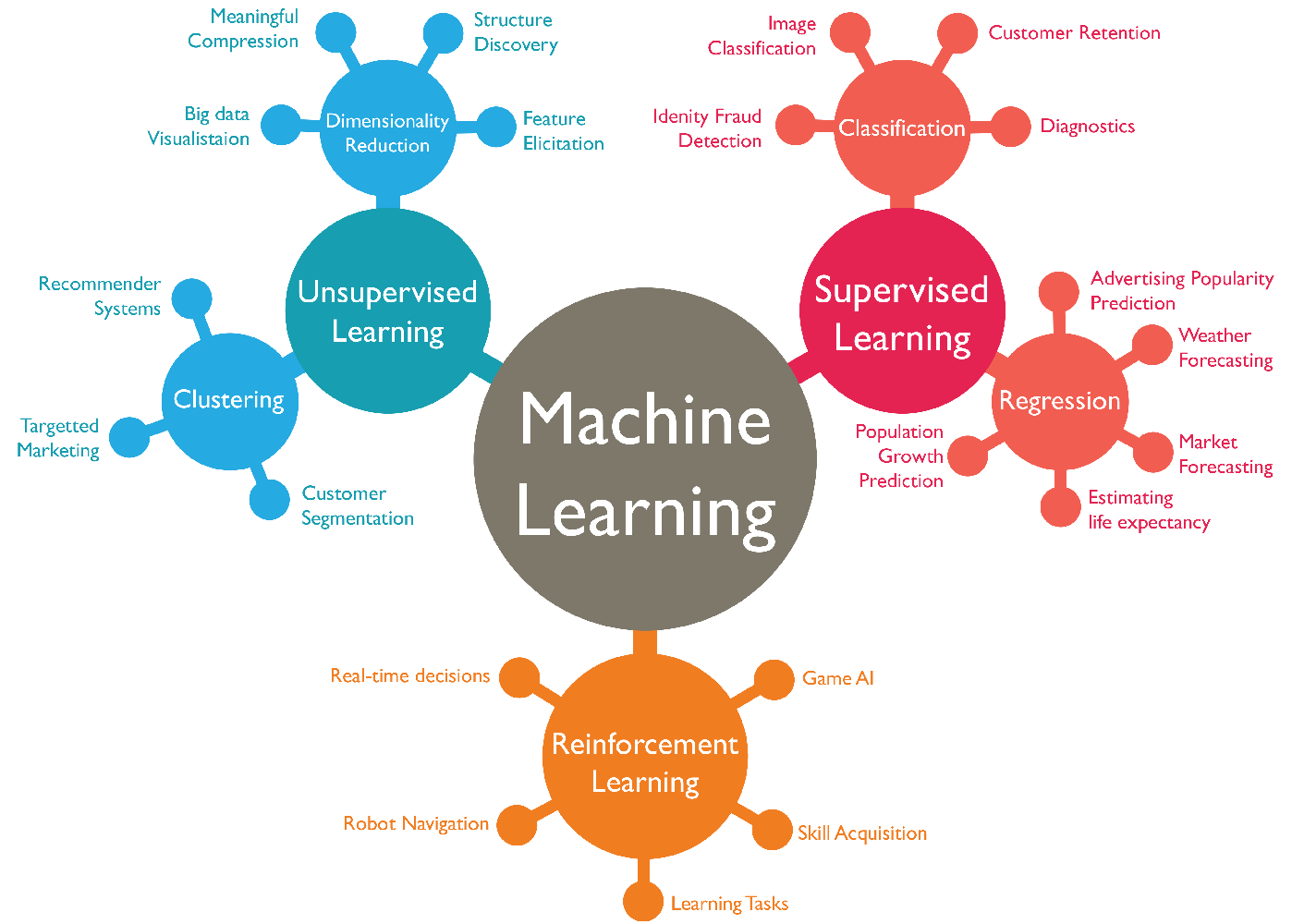
Types of Learning
Regression Example
- Goal: Establish the relationship between salary and demographic variables.
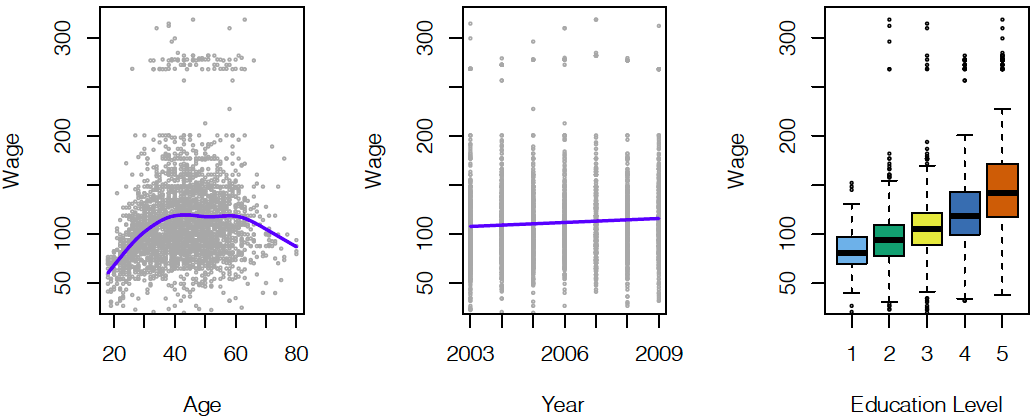
Source: ISL Fig. 1.1
Statistics Nah… Machine Learning Neat!
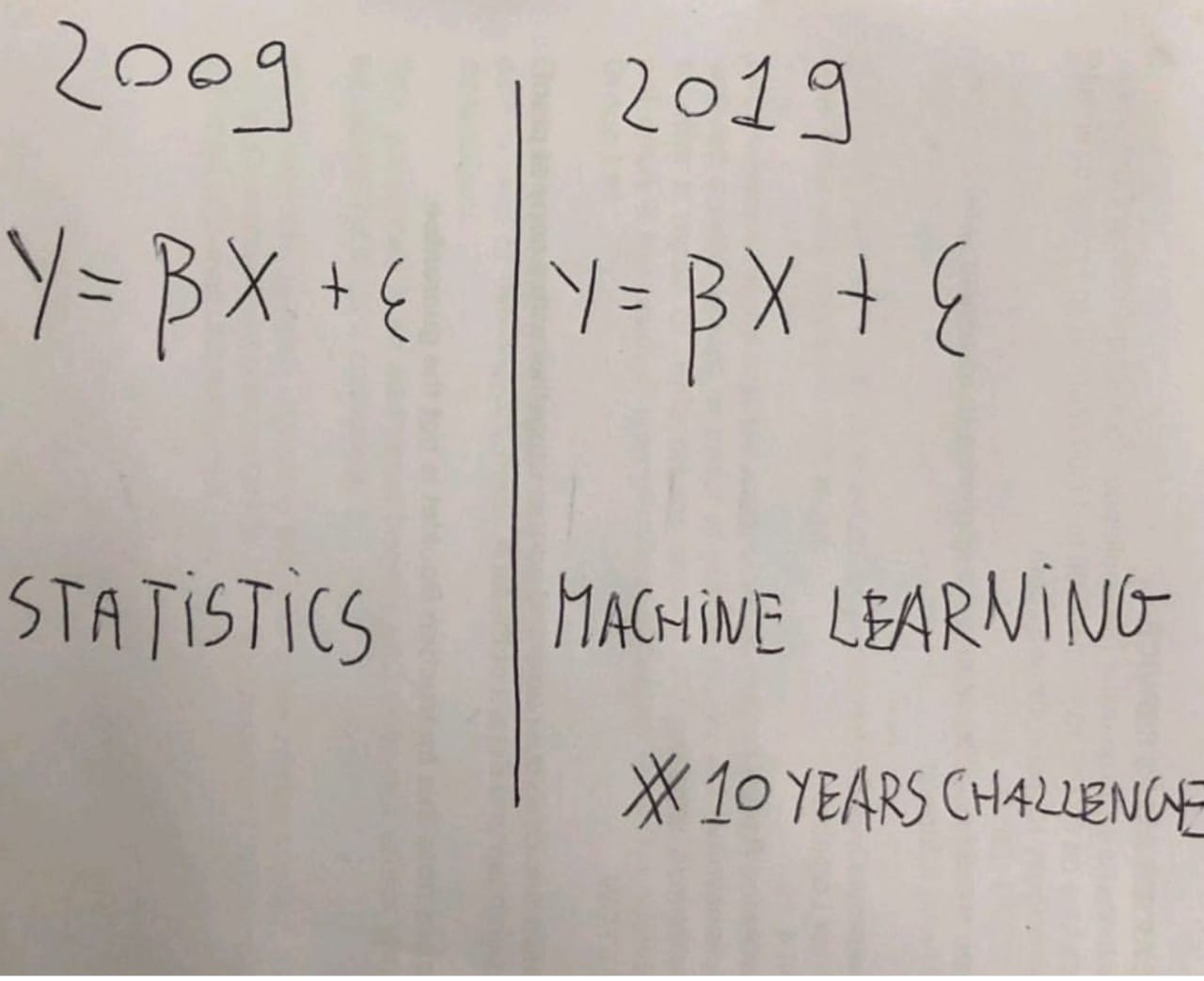
Source: https://towardsdatascience.com/the-actual-difference-between-statistics-and-machine-learning-64b49f07ea3
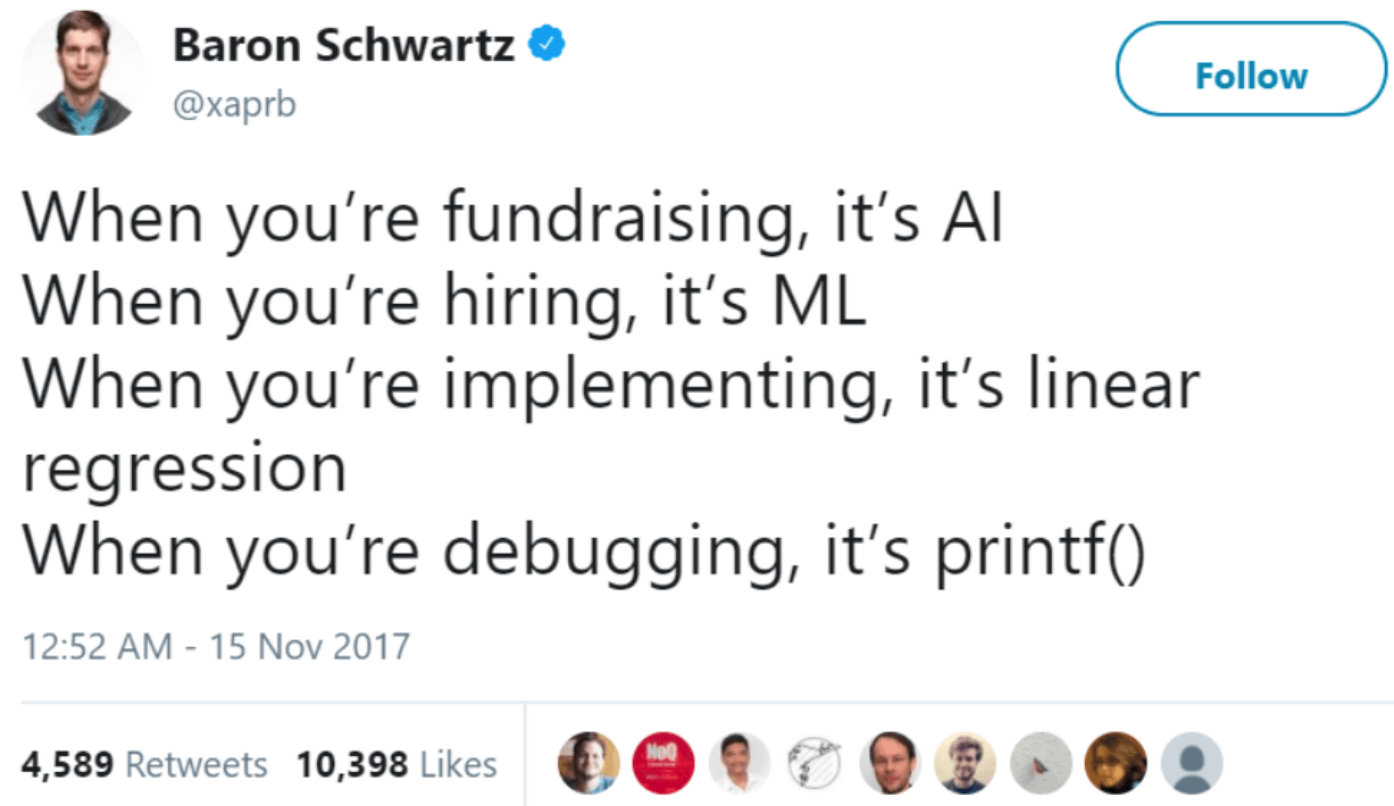
Statistics Nah… Machine Learning Neat!
Classification Example
- Goal: Build a customized spam filtering system

Source: http://penplusbytes.org/strategies-for-dealing-with-e-mail-spam/
Classification Example

- Data: 4601 emails sent to George at HP, before 2000. Each is labeled as spam or email.
- Inputs: relative frequencies of 57 of the commonly occurring words and punctuation marks.

Clustering Example
- Customer Segmentation: dividing customers into groups or clusters on the basis of common characteristics.
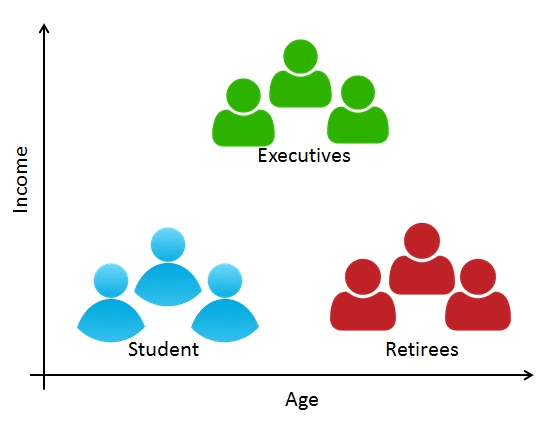
Source: https://www.datacamp.com/community/tutorials/introduction-customer-segmentation-python
Deep Learning
- An (artifical) neural network is a machine learning model inspired by the biological neural networks that constitute animal brains.


A neural network with several hidden layers is called a deep neural network, or deep learning.
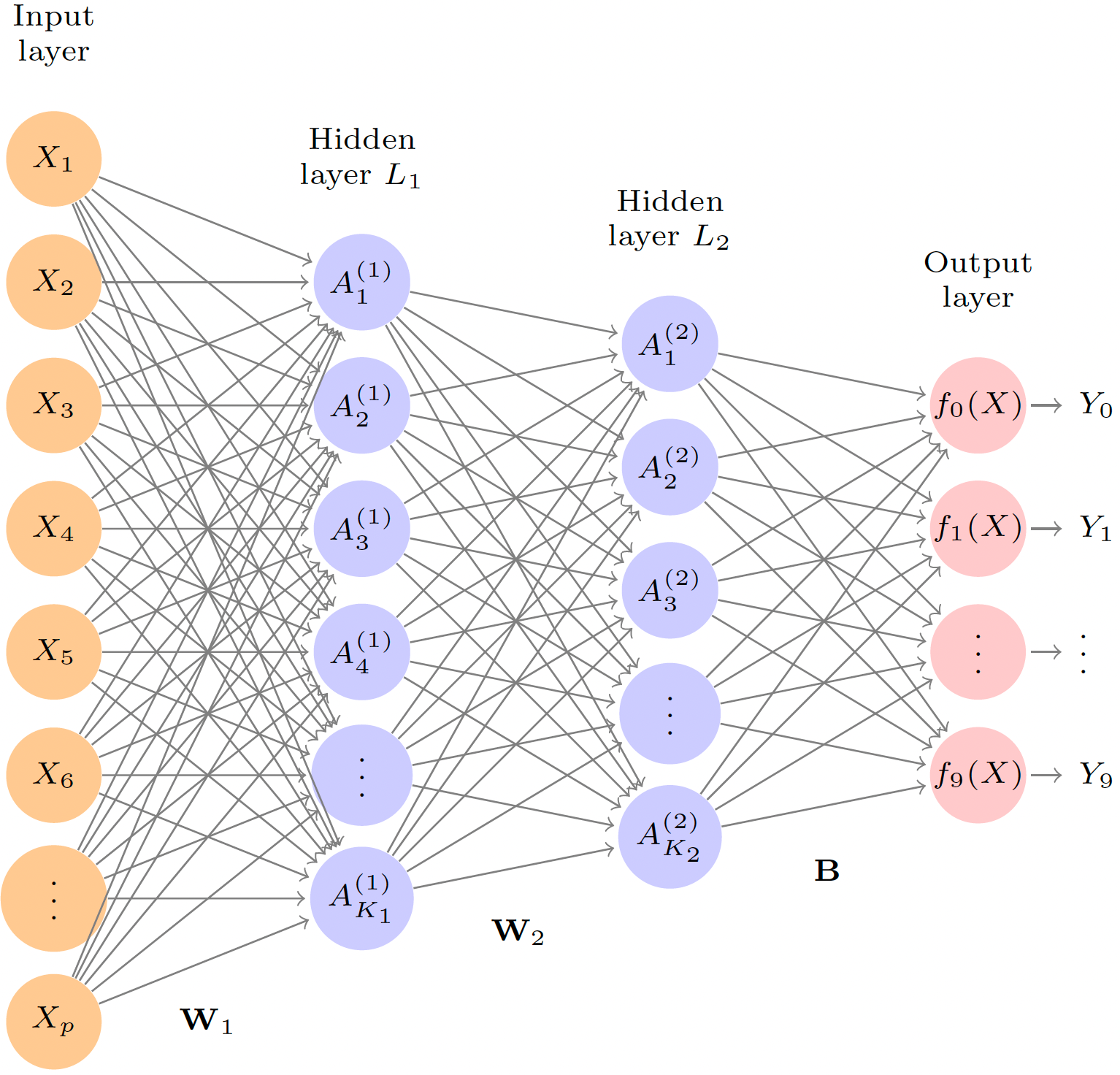
Source: ISL Ch 10
Accuracy and Interpretability Trade-Off
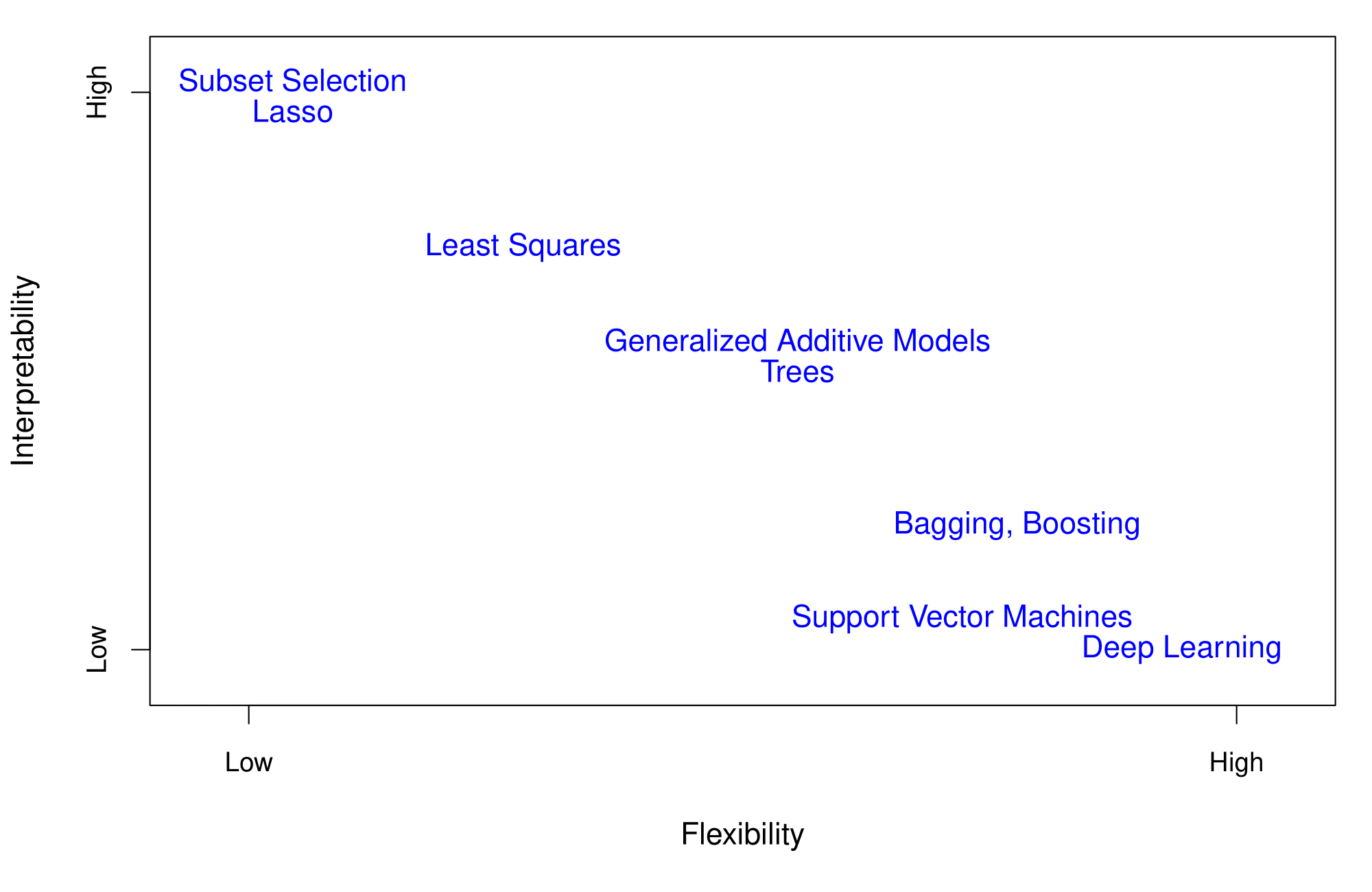
![]()