
Linear Regression 📈
MSSC 6250 Statistical Machine Learning
Why Multiple Linear Regression (MLR) Model
- Our target response may be affected by several factors.
- Total
sales\((Y)\) and amount of money spent on advertising onYouTube(YT) \((X_1)\),Facebook(FB) \((X_2)\),Instagram(IG) \((X_3)\).1


- Predict sales based on the three advertising expenditures and see which medium is more effective.
Fit Separate Simple Linear Regression (SLR) Models
❌ Fitting a separate SLR model for each predictor is not satisfactory.
Regression Hyperplane
- SLR: regression line
- MLR: regression hyperplane or response surface
- \(y = \beta_0 + \beta_1x_1 + \beta_{2}x_2 + \epsilon\)
- \(E(y \mid x_1, x_2) = 50 + 10x_1 + 7x_2\)
Response Surface
- \(y = \beta_0 + \beta_1x_1 + \beta_{2}x_2 + \beta_{11}x_1^2 + \beta_{22}x_2^2 + \beta_{12}x_1x_2 + \epsilon\)
- \(E(y \mid x_1, x_2) = 800+10x_1+7x_2 -8.5x_1^2-5x_2^2- 4x_1x_2\)
- 😎 🤓 A linear regression model can describe a complex nonlinear relationship between the response and predictors!
Geometry of Least Squares Estimation
Extrapolation
- Regression models are intended as interpolation equations over the range of the regressors used to fit the model.
Note
Do not use regression for time series forecasting!
Regression is Not for Causal Inference

Test for significance
Test for significance: Determine if there is a linear relationship between the response and any of the regressor variables.
\(H_0: \beta_1 = \beta_2 = \cdots = \beta_k = 0 \quad H_1: \beta_j \ne 0 \text{ for at least one } j\)

\(\sum_{i=1}^n(y_i - \overline{y})^2 = \sum_{i=1}^n(\hat{y}_i - \overline{y})^2 + \sum_{i=1}^n(y_i - \hat{y}_i)^2\)
Reject \(H_0\) if \(F_{test} > F_{\alpha, k, n - k - 1}\).
What is the sample statistic we use to accesses how well the model fits the data?
Normal Equations
\((\bf X' \bf X) \bf b = \bf X' \bf y\)
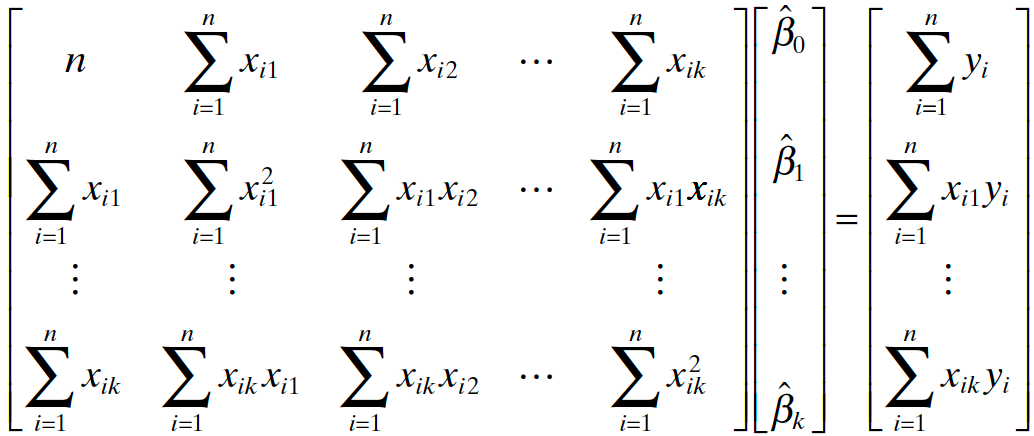
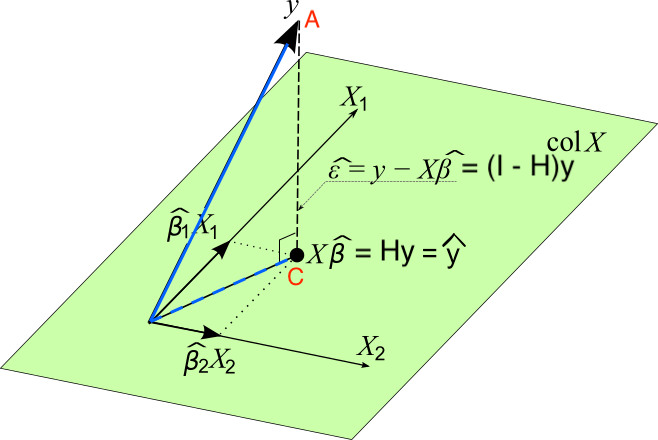
Geometrical Interpretation of Least Squares
\(Col({\bf X}) = \{ {\bf Xb}: {\bf b} \in {\bf R}^{k+1} \}\), \({\bf y} \notin Col({\bf X})\)
\(\hat{{\bf y}} = {\bf Xb} = {\bf H} {\bf y} \in Col({\bf X})\)
\(\small {\bf e} = ({\bf y - \hat{\bf y}}) = ({\bf y - X b}) = ({\bf I} - {\bf H}) {\bf y} \perp Col({\bf X})\)
\({\bf X}'{\bf e} = 0\)
Searching for \(\bf b\) that minimizes \(SS_{res}\) is equivalent to locating the point \({\bf Xb} \in Col({\bf X})\) \((C)\) that is as close to \(\bf y\) \((A)\) as possible!
Basic Principles
For a general function \(f(\mathbf{x})\) to be minimized with respect to (w.r.t.) \(\mathbf{x}\in \mathbf{R}^{p}\), we have
- First-Order Necessary Condition:
If \(f\) is continuously differentiable in an open neighborhood of local minimum \(\mathbf{x}^\ast\), then \(\nabla f(\mathbf{x}^\ast) = \mathbf{0}\).
Taylor Expansion
\[f(\mathbf{x}^\text{new}) \approx f(\mathbf{x}) + \nabla f(\mathbf{x}) (\mathbf{x}^\text{new} - \mathbf{x})\]
- Whether \(\nabla f(\mathbf{x})\) is positive or negative, we can always find a new point \(\mathbf{x}^\text{new}\) that makes \(\nabla f(\mathbf{x}) (\mathbf{x}^\text{new} - \mathbf{x})\) less than 0, so that \(f(\mathbf{x}^\text{new}) < f(\mathbf{x})\).
\(\nabla f(\mathbf{x}^\ast) = \mathbf{0}\) is only a necessary condition, not a sufficient condition.
\(x = 1\) is a local minimizer, not a global one.
Demo \(SS_{res}\) Contour
The objective function is \(\ell(\boldsymbol \beta) = \frac{1}{2n}||\mathbf{y} - \mathbf{X} \boldsymbol \beta ||^2\) with solution \({\bf b} = \left(\mathbf{X}'\mathbf{X}\right)^{-1} \mathbf{X}'\mathbf{y}\).
Code
set.seed(2024)
n <- 200
# create some data with linear model
X <- MASS::mvrnorm(n, c(0, 0), matrix(c(1, 0.7, 0.7, 1), 2, 2))
y <- rnorm(n, mean = 2 * X[, 1] + X[, 2])
beta1 <- seq(-1, 4, 0.005)
beta2 <- seq(-1, 4, 0.005)
allbeta <- data.matrix(expand.grid(beta1, beta2))
rss <- matrix(apply(allbeta, 1,
function(b, X, y) sum((y - X %*% b) ^ 2), X, y),
length(beta1), length(beta2))
# quantile levels for drawing contour
quanlvl = c(0.01, 0.025, 0.05, 0.2, 0.5, 0.75)
# plot the contour
contour(beta1, beta2, rss, levels = quantile(rss, quanlvl), las = 1)
box()
# the truth
b <- solve(t(X) %*% X) %*% t(X) %*% y
points(b[1], b[2], pch = 19, col = "blue", cex = 2)
Demo Gradient Descent
- Set \(\boldsymbol{\beta}^{(0)} = \mathbf{0}\), \(\delta = 0.2\)
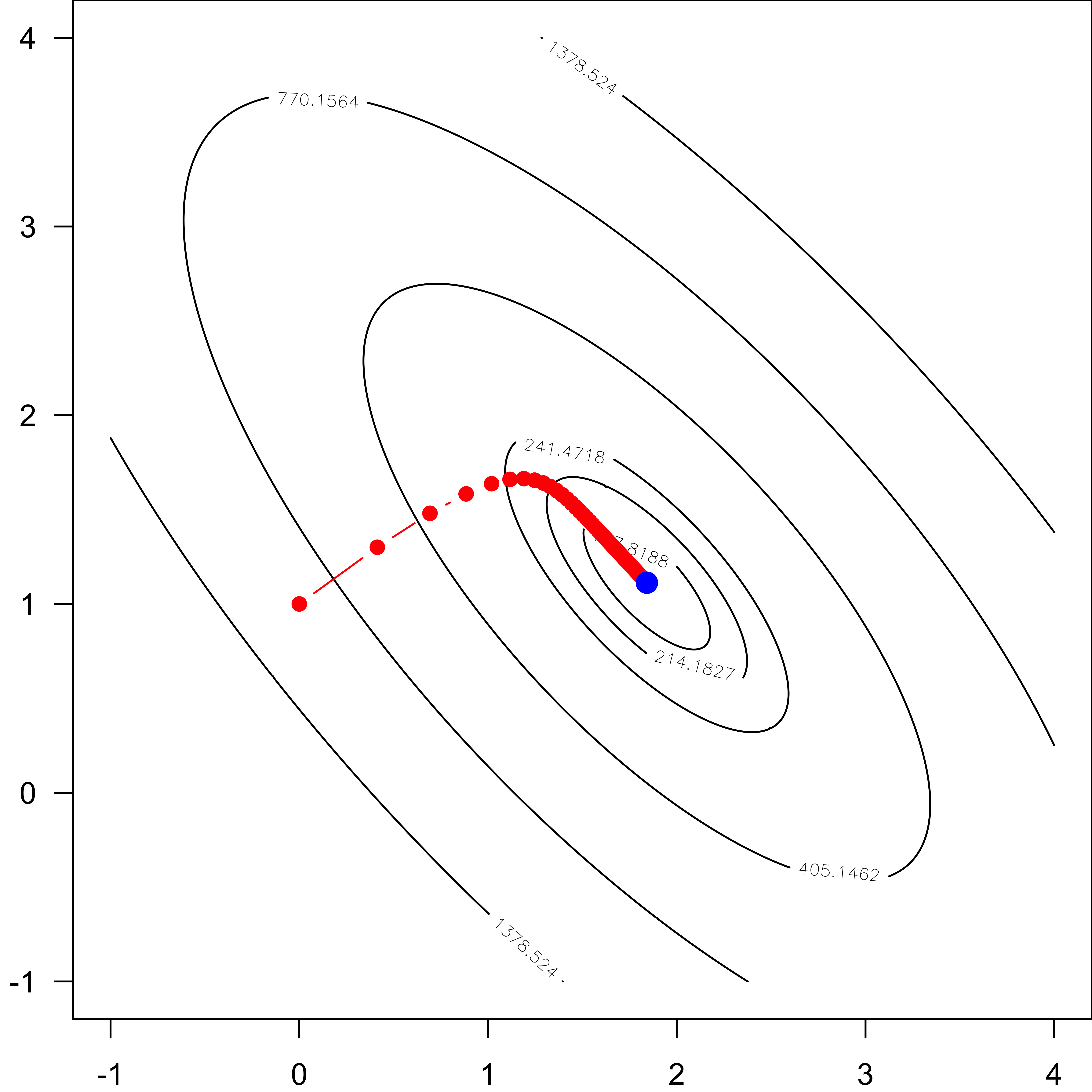
Demo Effect of \(\delta\)

Revisit optim()
optim(par, fn, gr = NULL, ...,
method = c("Nelder-Mead", "BFGS", "CG", "L-BFGS-B", "SANN", "Brent"),
lower = -Inf, upper = Inf,
control = list(), hessian = FALSE)- If gradient is known, we provide this information in the argument
gr =to avoid numerically approximating the gradient.- faster convergence
- more precise
![]()