[,1] [,2]
[1,] 50.3 -49.7
[2,] -49.7 50.3Ridge Regression and Cross Validation
MSSC 6250 Statistical Machine Learning
When OLS Doesn’t Work Well: Optimization Perspective
\(\beta_1 = \beta_2 = 1\) and \(\mathrm{Corr}(x_1, x_2) = 0.99\)
The relatively “flat” valley in the objective function walks along the eigen-vector of \({\bf X}'{\bf X}\) having the smallest eigen-value.
When OLS Doesn’t Work Well: Optimization Perspective
- A little change in the training set perturbs the objective function. The LSEs lie on a valley centered around the truth.
When OLS Doesn’t Work Well: High Variance
The optimizer could land anywhere along the valley, leading to large variance of the LSE.
Over many simulation runs, the LSE lies around the line of \(\beta_1 + \beta_2 = 2\), the direction of the eigen-vector of the smallest eigen-value.
Remedy for Large Variance and Large-\(p\)-small-\(n\)
Make \({\bf X}'{\bf X}\) invertible when \(p > n\) by regularizing coefficient behavior!
A good estimator balances bias and variance well, or minimizes the mean square error \[\text{MSE}(\hat{\beta}) = E[(\hat{\beta} - \beta)^2] = \mathrm{Var}(\hat{\beta}) + \text{Bias}(\hat{\beta})^2\]
Find a biased estimator \(\hat{\boldsymbol \beta}\) that has smaller variance and MSE than the LSE \({\bf b}\).
Ridge Penalty
\[\lambda \lVert \boldsymbol \beta\rVert^2_2 = \lambda \boldsymbol \beta' \mathbf{I}\boldsymbol \beta\]
The penalty contour is circle-shaped
Force the objective function to be more convex
A more stable or less varying solution
Geometrical Meaning of Ridge Regression
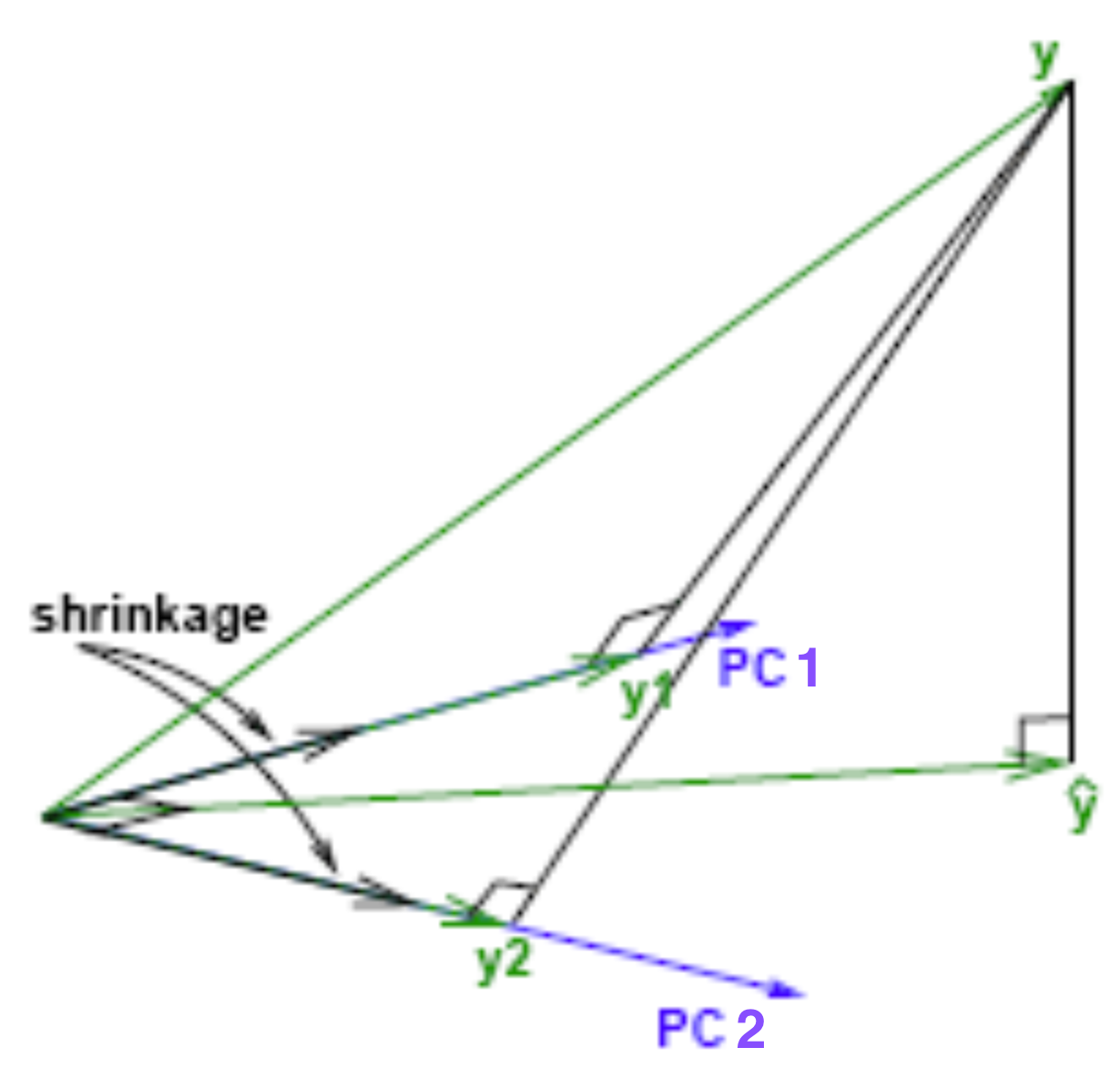
More Convex Loss Function
- Adding a ridge penalty forces the objective to be more convex due to the added eigenvalues.
The Bias-variance Tradeoff
- As \(\lambda \downarrow\), bias \(\downarrow\) and variance \(\uparrow\)
- As \(\lambda \uparrow\), bias \(\uparrow\) and variance \(\downarrow\)
Lower Test MSE
When \(b_j\) are variable or \(p > n\), ridge regression could have lower test MSE and better predictive performance.
Squared bias (black)
Variance (green)
\(\text{MSE}_{\texttt{Tr}}\) (purple)
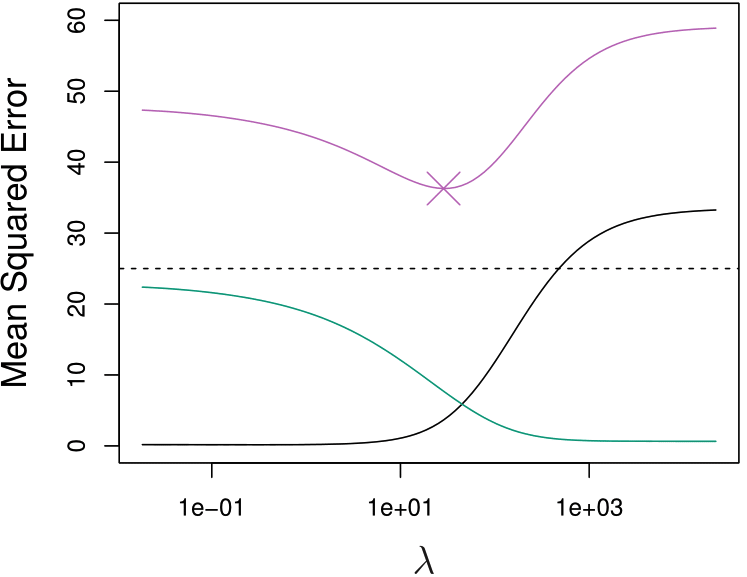
Ridge Trace
- Select a value of \(\lambda\) at which the ridge estimates are stable.
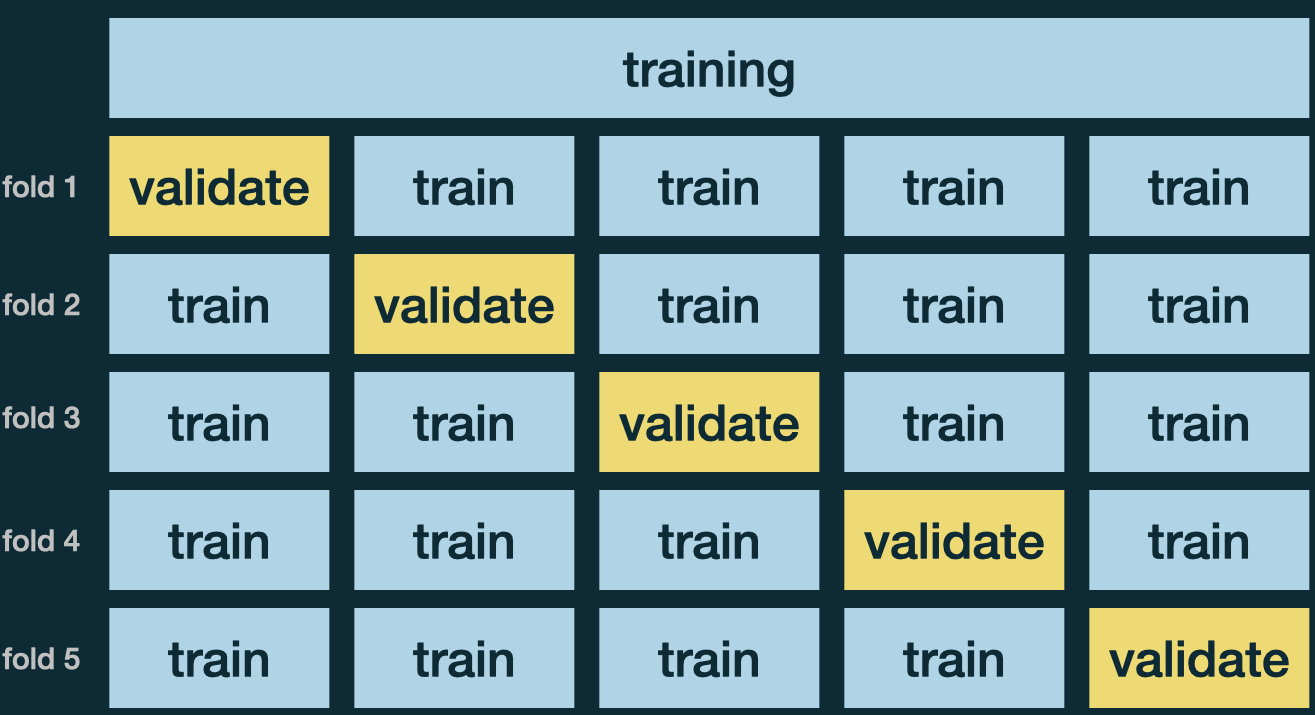
\(k\)-Fold Cross Validation
Randomly divide the training data into \(k\) folds, of approximately equal size.
Use 1 fold for validation to compute MSE, and the remaining \(k - 1\) partitions for training.
Repeat \(k\) times. Each time a different fold is treated as a validation set.
Average \(k\) metrics, \(\text{MSE}_{CV} = \frac{1}{k}\sum_{i=1}^k\text{MSE}_i\).
Use the CV estimate \(\text{MSE}_{CV}\) to select the “best” tuning parameter.
glmnet package ![]()
The parameter
alphacontrols the ridge (alpha = 0) and lasso (alpha = 1) penalties.Supply a decreasing sequence of
lambdavalues.lm.ridge()use \(SS_{res}\) and \(n\lambda\), whileglmnet()use \(\text{MSE}_{\texttt{Tr}}\) and \(\lambda\).Argument
xshould be a matrix.
Note
-
lm.ridge()andglmnet()coefficients do not match exactly, specially when transforming back to original scale. - No need to worry too much as we focus on predictive performance.
\(k\)-Fold Cross Validation using cv.glmnet()1
- The \(\lambda\) values are automatically selected, on the \(\log_{e}\) scale.
Determine \(\lambda\)
[1] 2.75[1] 16.111 x 1 sparse Matrix of class "dgCMatrix"
s1
(Intercept) 21.11734
cyl -0.37134
disp -0.00525
hp -0.01161
drat 1.05477
wt -1.23420
qsec 0.16245
vs 0.77196
am 1.62381
gear 0.54417
carb -0.54742Generalized Cross-Validation
Select the best \(\lambda\) that produces the smallest GCV.
![]()