
| lcavol | lweight | age | lbph | svi | lcp | gleason | pgg45 | lpsa | train |
|---|---|---|---|---|---|---|---|---|---|
| -0.580 | 2.77 | 50 | -1.386 | 0 | -1.39 | 6 | 0 | -0.431 | TRUE |
| -0.994 | 3.32 | 58 | -1.386 | 0 | -1.39 | 6 | 0 | -0.163 | TRUE |
| -0.511 | 2.69 | 74 | -1.386 | 0 | -1.39 | 7 | 20 | -0.163 | TRUE |
| -1.204 | 3.28 | 58 | -1.386 | 0 | -1.39 | 6 | 0 | -0.163 | TRUE |
| 0.751 | 3.43 | 62 | -1.386 | 0 | -1.39 | 6 | 0 | 0.372 | TRUE |
| -1.050 | 3.23 | 50 | -1.386 | 0 | -1.39 | 6 | 0 | 0.765 | TRUE |
| 0.737 | 3.47 | 64 | 0.615 | 0 | -1.39 | 6 | 0 | 0.765 | FALSE |
| 0.693 | 3.54 | 58 | 1.537 | 0 | -1.39 | 6 | 0 | 0.854 | TRUE |
Feature Selection and LASSO ![]()
MSSC 6250 Statistical Machine Learning
Subset Selection
- MSSC 5780 slides and ISL Sec. 6.1
- Identify a subset of all the candidate predictors with the best OLS performance.
- Best subset selection
olsrr::ols_step_best_subset() - Forward stepwise selection
olsrr::ols_step_forward_p() - Backward stepwise elimination
olsrr::ols_step_backward_p() - Hybrid stepwise selection
olsrr::ols_step_both_p()
- Best subset selection

Lasso (Least Absolute Shrinkage and Selection Operator) ![]()
\(\ell_2\) vs. \(\ell_1\)
- Ridge shrinks big coefficients much more than lasso.
- Lasso has larger penalty on small coefficients.
cv.glmnet(alpha = 1)
Variable Selection Property and Shrinkage
The proportion of times a variable has a non-zero parameter estimation.
\(\mathbf{y}= \mathbf{X}\boldsymbol \beta + \epsilon = \sum_{j = 1}^p X_j \times 0.4^{\sqrt{j}} + \epsilon\)
\(p = 20\), \(\epsilon \sim N(0, 1)\) and replicate 100 times.
Bias-Variance Trade-off
Geometric Representation of Optimization
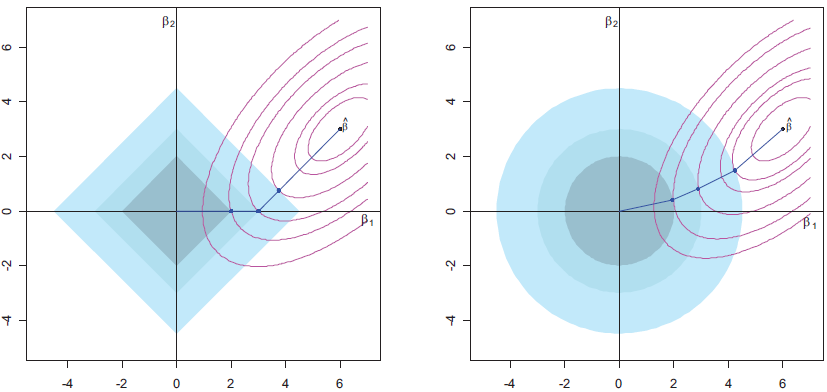
What do the constraints look like geometrically?
When \(p = 2\),
- the \(\ell_1\) constraint is \(|\beta_1| + |\beta_2| \leq s\) (diamond)
- the \(\ell_2\) constraint is \(\beta_1^2 + \beta_2^2 \leq s\) (circle)
Way of Shrinking (\(p = 1\) and standardized \(x\))
Lasso Soft-thresholding
\[\begin{align} \widehat{\beta}^\text{l} &= \begin{cases} b - \lambda/2 & \text{if} \quad b > \lambda/2 \\ 0 & \text{if} \quad |b| < \lambda/2 \\ b + \lambda/2 & \text{if} \quad b < -\lambda/2 \\ \end{cases} \end{align}\]
Ridge Proportional shrinkage
\[\begin{align} \widehat{\beta}^\text{r} = \dfrac{b}{1+\lambda}\end{align}\]
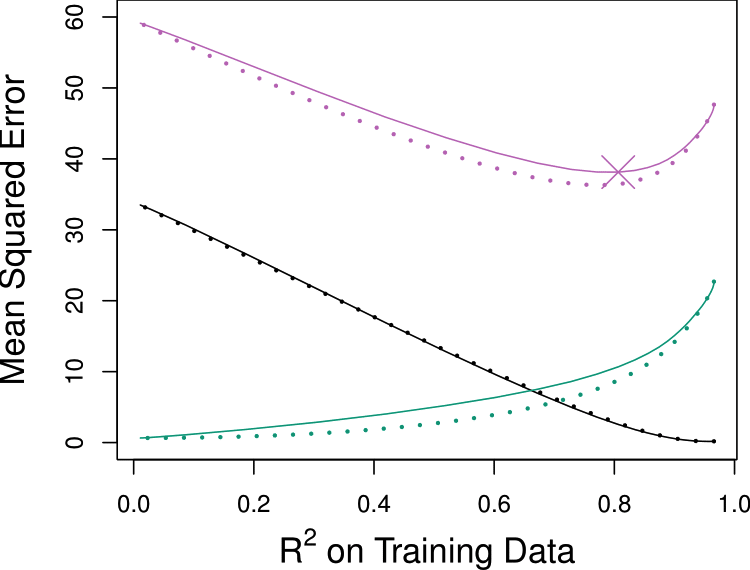
Predictive Performance
Perform well (lower test MSE) when
Lasso (—)
A relatively small number of \(\beta_j\)s are substantially large, and the remaining \(\beta_k\)s are small or equal to zero.
Reduce more bias
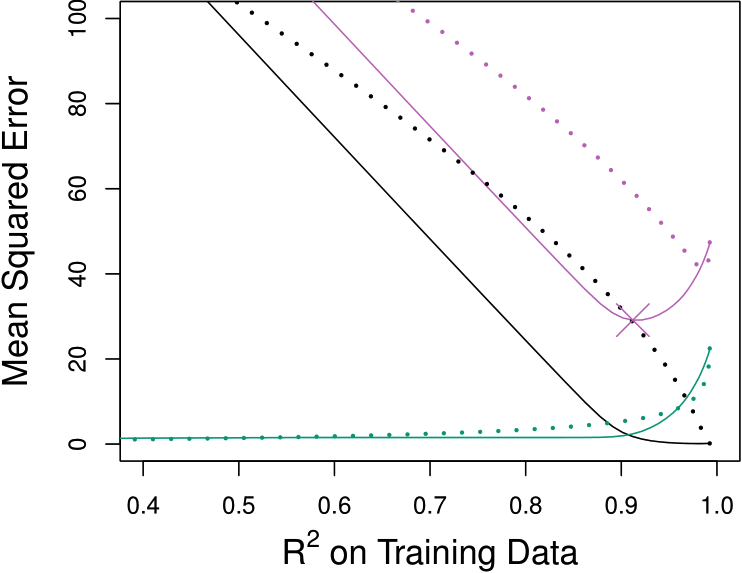
Ridge (\(\cdots\cdots\))
The response is a function of many predictors, all with coefficients of roughly equal size.
Reduce more variance
Other Topics
- Combination \(\ell_1\) and \(\ell_2\): Elastic net penalty (Zou and Hastie, 2005)
\[\lambda \left[ (1 - \alpha) \lVert \boldsymbol \beta\rVert_2^2 + \alpha \lVert\boldsymbol \beta\lVert_1 \right]\]
- General \(\ell_q\) penalty: \(\lambda \sum_{j=1}^p |\beta_j|^q\)
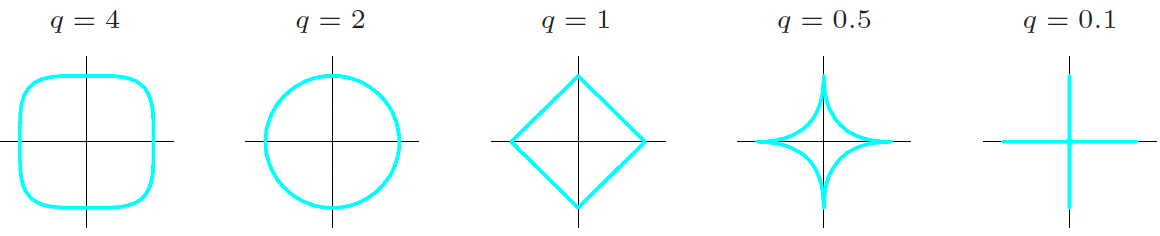
Other Topics
-
Algorithms
- Shooting algorithm (Fu 1998)
- Least angle regression (LAR) (Efron et al. 2004)
- Coordinate descent (Friedman et al 2010) (used in
glmnet)
-
Variants
- Adaptive Lasso
- Group Lasso
- Bayesian Lasso, etc.
![]()