
Bayesian Linear Regression
MSSC 6250 Statistical Machine Learning
Frequentist or Bayesian?
- Totals 4-5: your thinking is frequentist
- Totals 9-12: your thinking is Bayesian

- Totals 6-8: you see strengths in both philosophies
The Meaning of Probability: Relative Frequency
- The frequentist interprets probability as the long-run relative frequency of a repeatable experiment.
The probability that some outcome of a process will be obtained is defined as
the relative frequency with which that outcome would be obtained if the process were repeated a large number of times independently under similar conditions.
Frequency Relative Frequency
Heads 4 0.4
Tails 6 0.6
Total 10 1.0
---------------------
Frequency Relative Frequency
Heads 512 0.512
Tails 488 0.488
Total 1000 1.000
---------------------- If we repeat tossing the coin 10 times, the probability of obtaining heads is 40%.
- If 1000 times, the probability is 51.2%.

Issues of Relative Frequency
- 😕 How large of a number is large enough?
- 😕 Meaning of “under similar conditions”
- 😕 The relative frequency is reliable under identical conditions?
- 👉 We only obtain an approximation instead of exact value.
- 😂 How do you compute the probability that Chicago Cubs wins the World Series next year?

The Meaning of Probability: Relative Plausibility
- In the Bayesian philosophy, a probability measures the relative plausibility of an event.
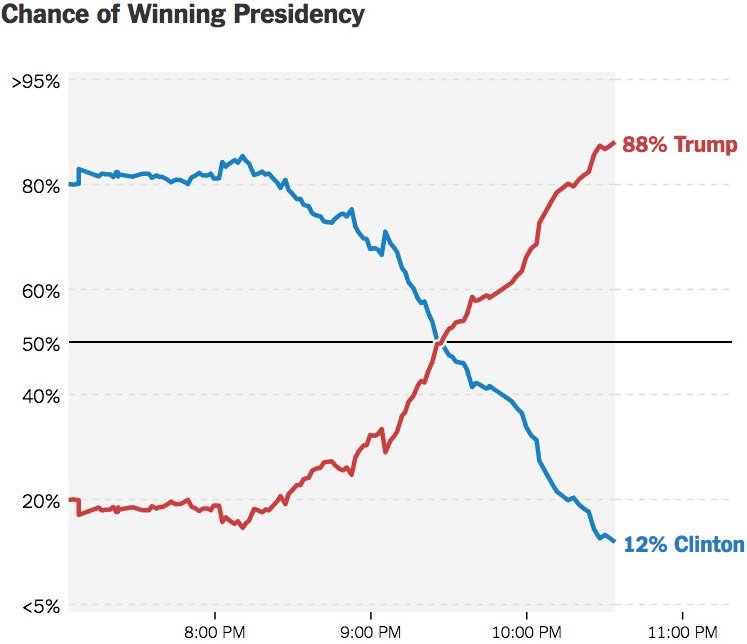
- For the statement “candidate A has a 0.9 probability of winning”
- A frequentist might
- say the conclusion is wrong
- weirdly say in long-run hypothetical repetitions of the election, candidate A would win roughly 90% of the time.
- A Bayesian would say based on analysis the candidate A is 9 times more likely to win than to lose.
- A frequentist might
Everybody Changes Their Mind
How can we live if we don’t change? - Beyoncé. Lyric from “Satellites.”
Using data and prior beliefs to update our knowledge (posterior), and repeating.
We continuously update our knowledge about the world as we accumulate lived experiences, or collect data.
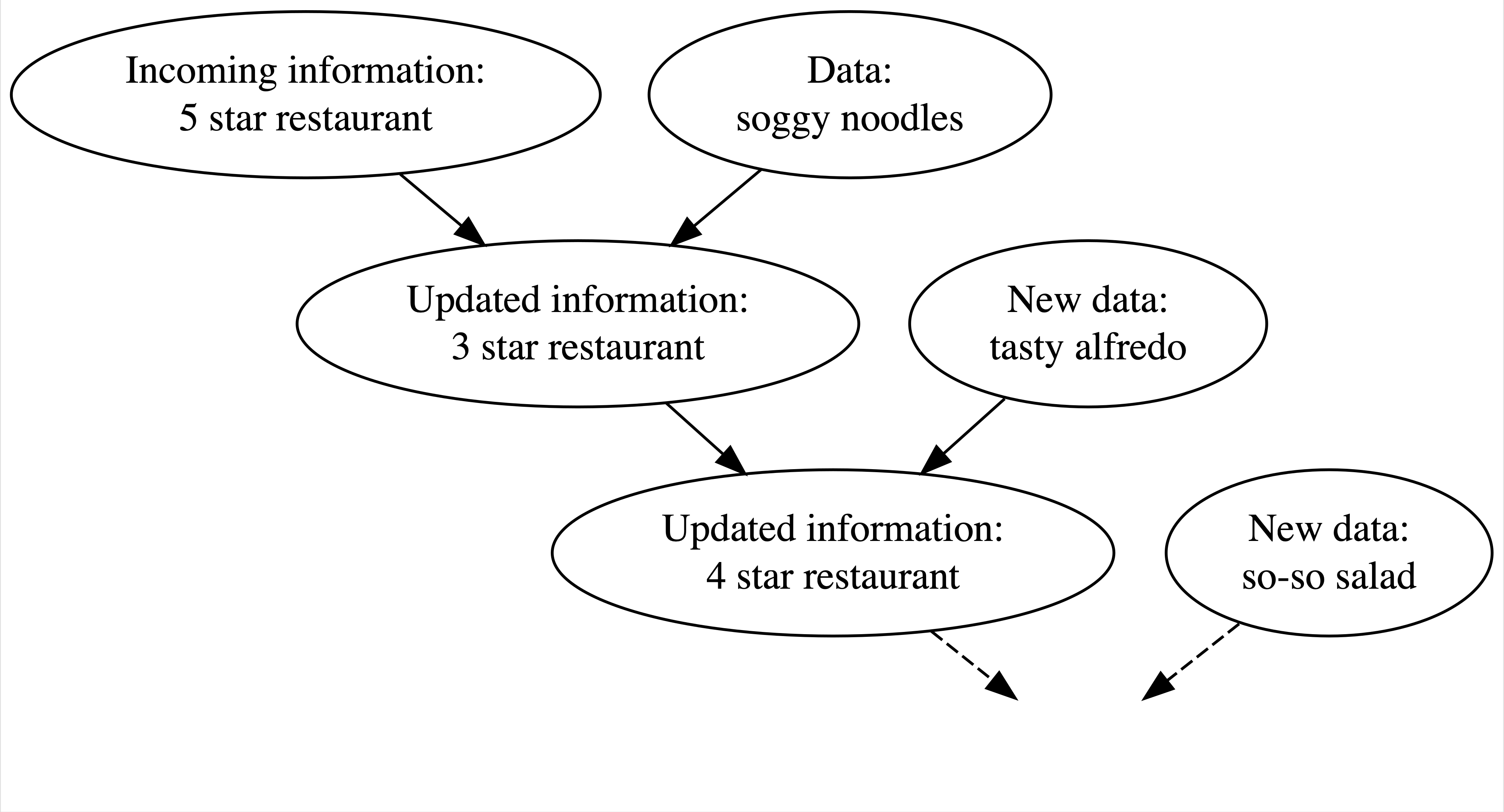
Fig 1.1 of https://www.bayesrulesbook.com/. The figures not being sourced come from this book too.
Bayesian Knowledge-building Process
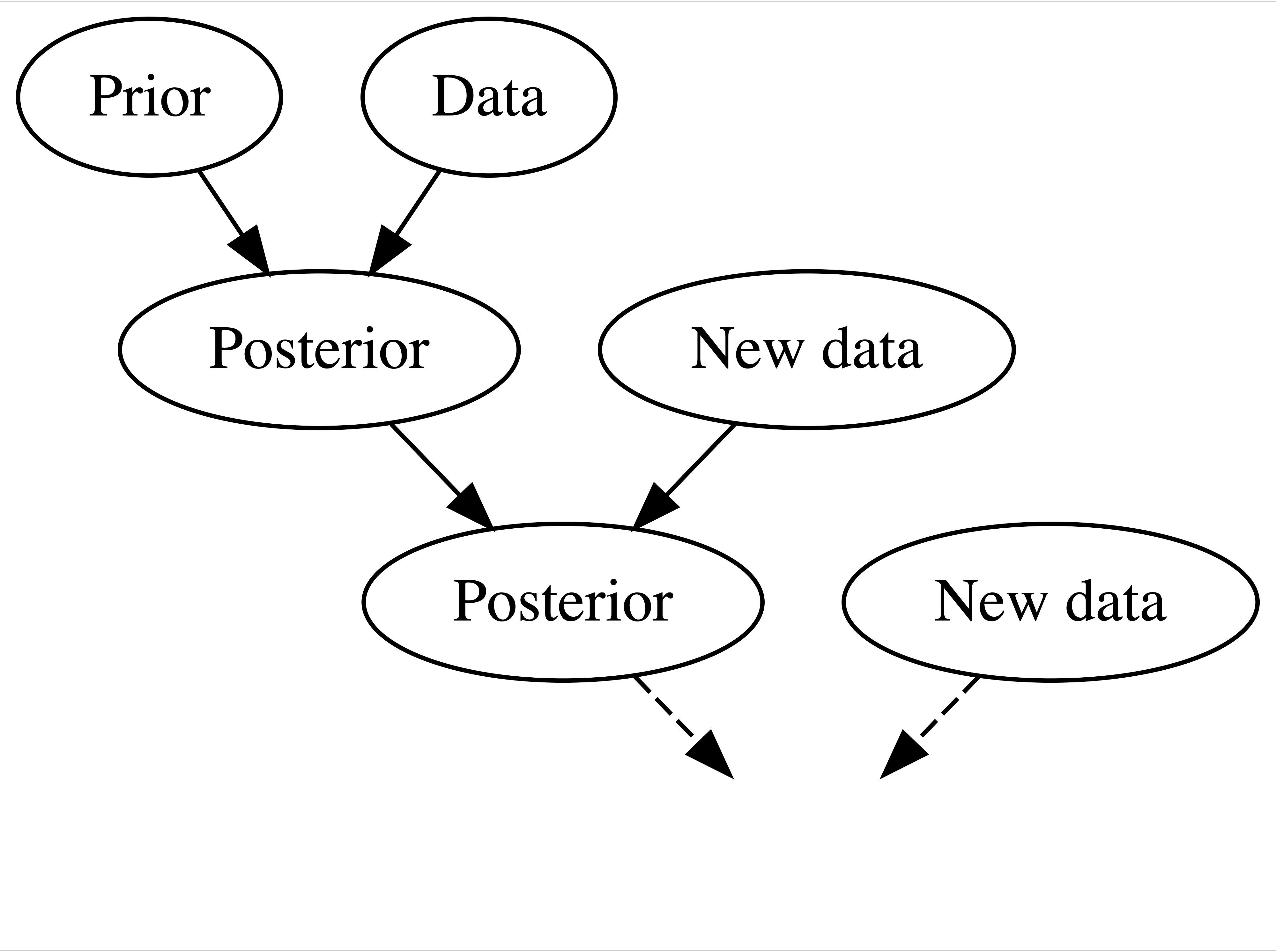
Frequentist Relys on (Limited) Data Only
- In Question 3, in a frequentist analysis, “8 out of 8” is “8 out of 8” no matter if it’s in the context of Ben’s coins or Emma’s sweeteners.
- Equally confident conclusions that Ben can predict coin flips and Emma can distinguish between natural and artificial sweeteners.

- But do you really believe Ben’s claim 100%? 🤔 😕
- In fact, we judge their claim before evidence are collected, don’t we? 🤔
- You probably think Ben overstates his ability but Emma’s claim sounds relatively reasonable, right?
The Bayesian Balancing
- Frequentist throws out all prior knowledge in favor of a mere 8 data points.
- Bayesian analyses balance and weight our prior experience/knowledge/belief and new data/evidence to judge a claim or make a conclusion.
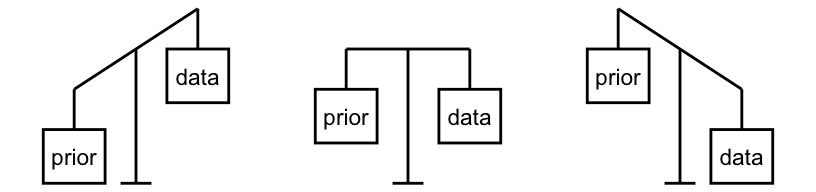
- We are not stubborn! If Ben had correctly predicted the outcome of 1 million coin flips, the strength of this data would far surpass that of our prior judgement, leading to a posterior conclusion that perhaps Ben is psychic!

Asking Different Questions
In Question 4,
- Bayesians answer (a) what’s the chance that I actually have COVID?
- Frequentists answer (b) if in fact I do not have COVID, what’s the chance that I would’ve gotten this positive test result?
| Test Positive | Test Negative | Total | |
|---|---|---|---|
| COVID | 3 | 1 | 4 |
| No COVID | 9 | 87 | 96 |
| Total | 12 | 88 | 100 |
\(H_0\): Do not have COVID vs. \(H_1\): Have COVID
A frequestist assesses the uncertainty of the observed data in light of an assumed hypothesis \(P(Data \mid H_0) = 9/96\)
A Bayesian assesses the uncertainty of the hypothesis in light of the observed data \(P(H_0 \mid Data) = 9/12\)
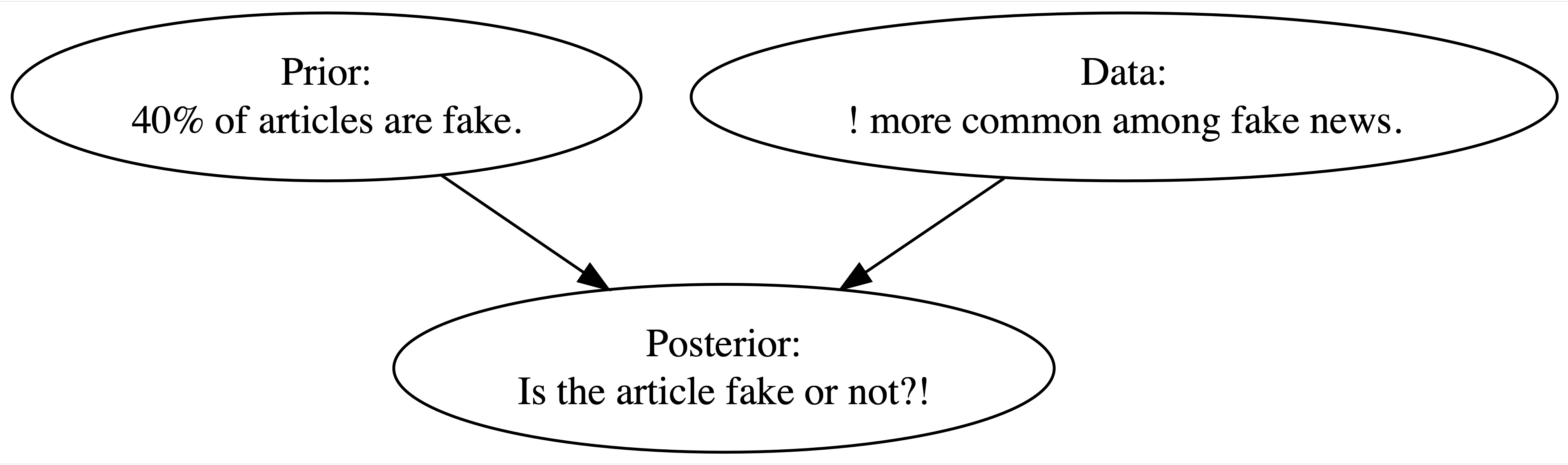
Fake News
- Tell if an incoming article is fake.
- Prior info: 40% of the articles are fake
type n percent
fake 60 0.4
real 90 0.6
Total 150 1.0
-
Data come in: Check several fake and real articles, and found
!is more consistent with fake news.
title_has_excl fake real
FALSE 44 88
TRUE 16 2
Total 60 90Bayesian Updating Rule
\(F\): an article is fake.
The prior probability model
| Event | \(F\) | \(F^c\) | Total |
|---|---|---|---|
| Probability \(P(\cdot)\) | 0.4 | 0.6 | 1 |
Bayesian Model for Events
title_has_excl fake real
FALSE 44 88
TRUE 16 2
Total 60 90\(D\): an article title has exclamation mark.
Conditional probability: \(P(D \mid F) = 16/60 = 0.27\); \(P(D \mid F^c) = 2/90 = 0.02\).
-
Opposite position:
- Know the incoming article used
!(observed data) - Don’t know whether or not the article is fake (what we want to decide).
- Know the incoming article used
- Compare \(P(D \mid F)\) and \(P(D \mid F^c)\) to ascertain the relative likelihoods of observed data \(D\) under different scenarios of the uncertain article status.
Motivation Example
- Michelle has decided to run for governor of Wisconsin.
- According to previous 30 polls,
- Michelle’s support is centered round 45%
- she polled at around 35% in the dreariest days and around 55% in the best days
- With this prior information, we’d like to estimate/update Michelle’s support by conducting a new poll.

Key: Describe prior and data information using probabilistic models.
- The parameter to be estimated is \(\theta\), the Michelle’s support, which is between 0 and 1.
Prior Distribution
- A popular probability distribution for probability is beta distribution, \(\text{beta}(\alpha, \beta)\), where \(\alpha > 0\) and \(\beta > 0\) are shape parameters.
\[\pi(\theta \mid \alpha, \beta) = \frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}\theta^{\alpha - 1}(1-\theta)^{\beta-1}\]

Prior Distribution
Likelihood
Posterior Distribution
Capital Bikeshare bayesrules::bikes Data in Washington, D.C.
Rows: 500
Columns: 2
$ rides <int> 654, 1229, 1454, 1518, 1362, 891, 1280, 1220, 1137, 1368, 13…
$ temp_feel <dbl> 64.7, 49.0, 51.1, 52.6, 50.8, 46.6, 45.6, 49.2, 46.4, 45.6, …
Tuning Prior Models
-
Prior understanding 1:
- On an average temperature day, say 65 or 70 degrees, there are typically around 5000 riders, though this average could be somewhere between 3000 and 7000.
- The prior information tells us something about \(\beta_0\), but the information has been centered.
- The centered intercept, \(\beta_{0c}\), reflects the typical ridership at the typical temperature.
\(\beta_{0c} \sim N(5000, 1000^2)\)
Tuning Prior Models
-
Prior understanding 2:
- For every one degree increase in temperature, ridership typically increases by 100 rides, though this average increase could be as low as 20 or as high as 180.
\(\beta_{1} \sim N(100, 40^2)\)
Tuning Prior Models
-
Prior understanding 3:
- At any given temperature, daily ridership will tend to vary with a moderate standard deviation of 1250 rides.
\(\sigma \sim \text{Exp}(0.0008)\) because \(\mathrm{E}(\sigma) = 1/\lambda = 1/0.0008 = 1250\)
Prior Model Simulation
- 100 prior plausible model lines \(\mu_{Y|X} = \beta_0 + \beta_1 X\)
Convergence Diagnostics
Convergence Diagnostics
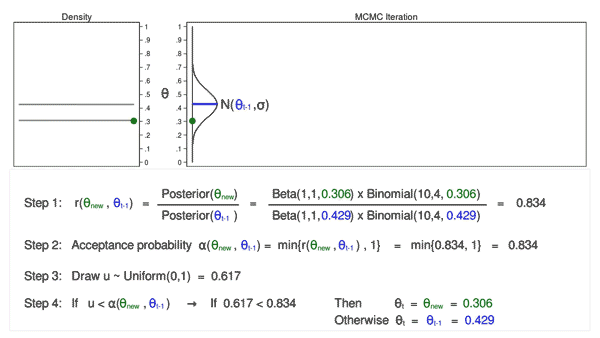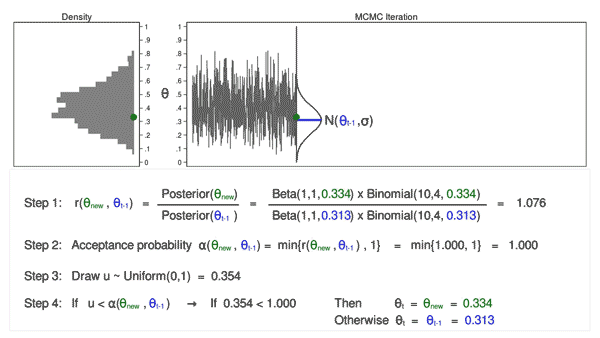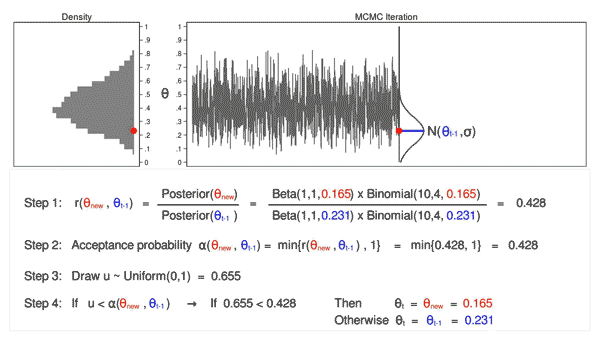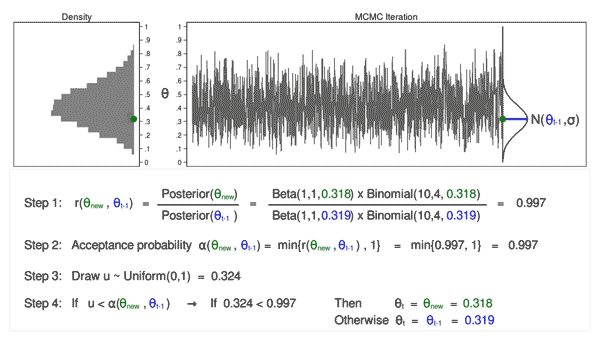
Source: https://blog.stata.com/2016/11/15/introduction-to-bayesian-statistics-part-2-mcmc-and-the-metropolis-hastings-algorithm/
Convergence Diagnostics
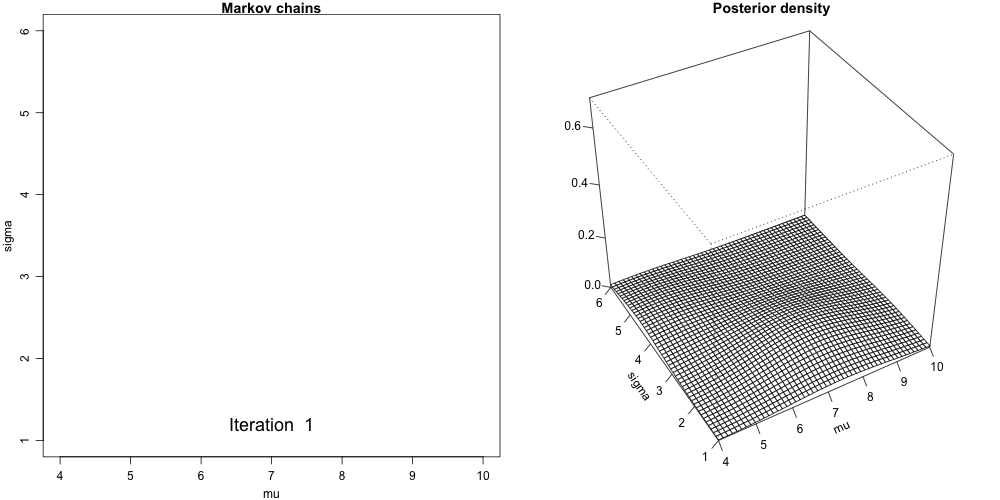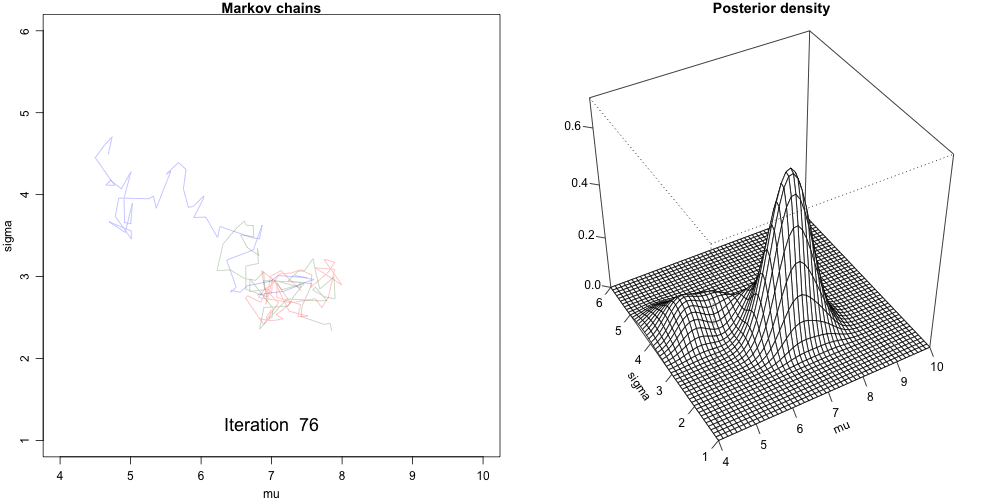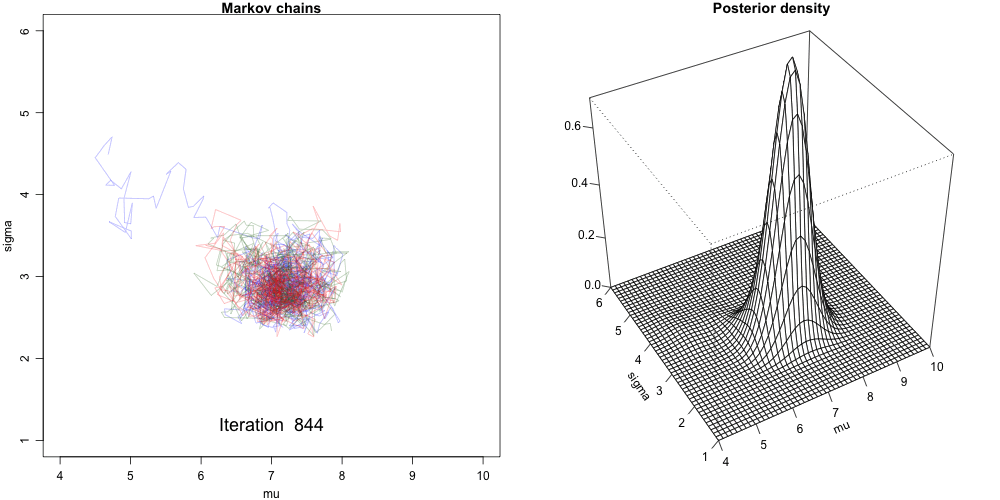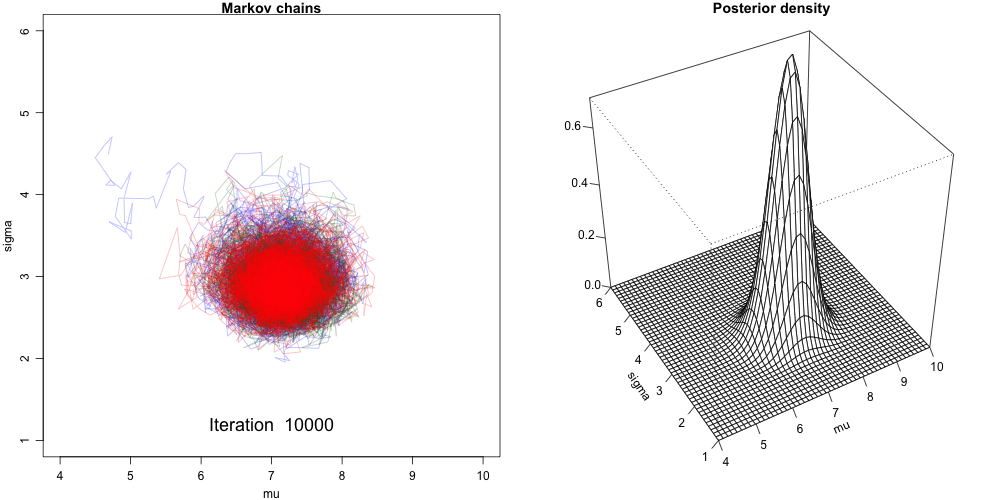
Convergence Diagnostics
Convergence Issues
-
Highly Autocorrelated Chain: Effective size is small, not many independent samples that are representative of the true posterior distribution.
- Run longer and thinning the chain
-
Slow Convergence: Need wait longer to have the chain reached a stable mixing zone that are representative of the true posterior distribution.
- Set a longer burn-in or warm-up period
Posterior Regression Lines
Posterior Predictive Draws
For each posterior draw \(\{\beta_0^{(t)}, \beta_1^{(t)}, \sigma^{(t)} \}_{t = 1}^{20000}\), we have the posterior predictive distribution \[Y_i^{(t)} \sim N\left(\beta_0^{(t)} + \beta_1^{(t)}X_i, \, (\sigma^{(t)})^2\right)\]
Ridge and Lasso Priors
Lasso
\[\beta_j \stackrel{iid}{\sim} \text{Laplace}\left(0, \tau(\lambda)\right)\]
Lasso solution is the posterior mode of \(\boldsymbol \beta\)
\[\boldsymbol \beta^{(l)} = \mathop{\mathrm{arg\,max}}_{\boldsymbol \beta} \,\,\, \pi(\boldsymbol \beta\mid \mathbf{y}, \mathbf{x})\]
Ridge
\[\beta_j \stackrel{iid}{\sim} N\left(0, \tau(\lambda)\right)\]
Ridge solution is the posterior mode/mean of \(\boldsymbol \beta\)
\[\boldsymbol \beta^{(r)} = \mathop{\mathrm{arg\,max}}_{\boldsymbol \beta} \,\, \, \pi(\boldsymbol \beta\mid \mathbf{y}, \mathbf{x})\]
Resources
![]()