
Clustering
MSSC 6250 Statistical Machine Learning
Clustering Methods
- Clustering: techniques for finding subgroups, or clusters, in a data set.
- Goal: Homogeneous within groups; heterogeneous between groups
-
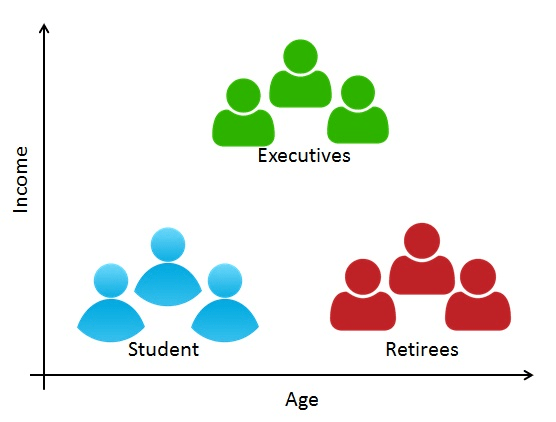
Customer/Marketing Segmentation
- Divide customers into clusters on age, income, etc.
- Each subgroup might be more receptive to a particular form of advertising, or more likely to purchase a particular product.
Source: https://shopup.me/blog/customer-segmentation-definition/
K-Means Clustering
Partition observations into \(K\) distinct, non-overlapping clusters: assign each to exactly one of the \(K\) clusters.
Must pre-specify the number of clusters \(K \ll n\).
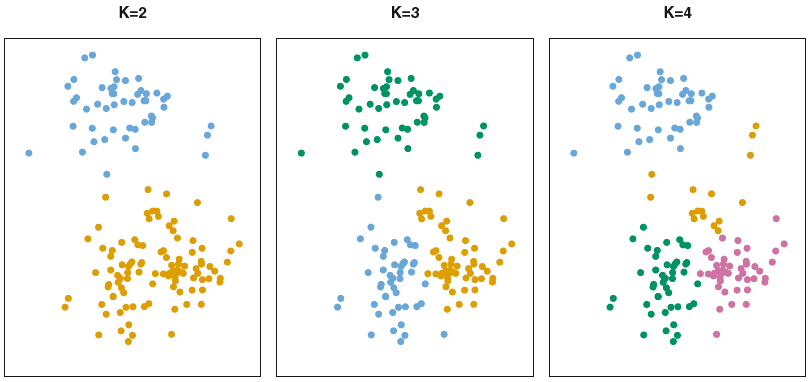
Source: Fig. 12.7 of ISL
K-Means Illustration
Random assignment

K-Means Algorithm
- Choose a value of \(K\).
- Randomly assign a number, from 1 to \(K\), to each of the observations.
- Iterate until the cluster assignments stop changing:
- [1] For each of the \(K\) clusters, compute its cluster centroid.
- [2] Assign each observation to the cluster whose centroid is closest.
K-Means Illustration
Compute the cluster centroid
K-Means Algorithm
- Choose a value of \(K\).
- Randomly assign a number, from 1 to \(K\), to each of the observations.
- Iterate until the cluster assignments stop changing:
- [1] For each of the \(K\) clusters, compute its cluster centroid.
- [2] Assign each observation to the cluster whose centroid is closest.
K-Means Illustration
Do a new assignment
K-Means Algorithm
- Choose a value of \(K\).
- Randomly assign a number, from 1 to \(K\), to each of the observations.
- Iterate until the cluster assignments stop changing:
- [1] For each of the \(K\) clusters, compute its cluster centroid.
- [2] Assign each observation to the cluster whose centroid is closest.
K-Means Illustration
Do a new assignment

Compute the cluster centroid
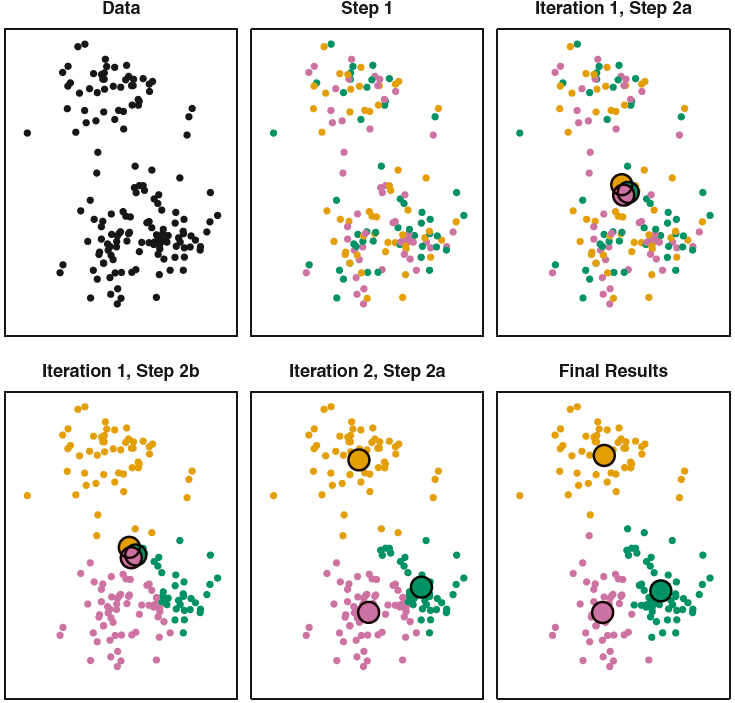
Source: ISL Figure 12.8
Clustering Mathematical Formulation
- \(C(\cdot): \{1, \ldots, n\} \rightarrow \{1, \ldots, K\}\) is a cluster assignment function or encoder that assigns the \(i\)th observation to the \(k\)th cluster, \(i \in \{1, \ldots, n\}\), \(k \in \{1, \ldots, K\}\), or \(C(i) = k\).
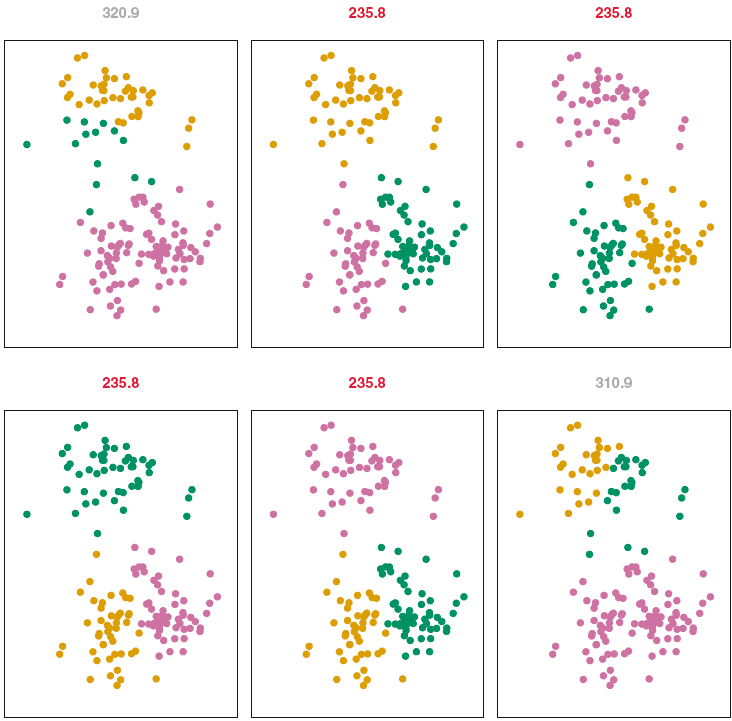
Seek a \(C(\cdot)\) that minimizes the within-cluster distance \[ \begin{align} W(C) = \frac{1}{2}\sum_{k=1}^K\sum_{(i, i'): C(i), C(i')=k} d(\mathbf{x}_i, \mathbf{x}_{i'}) \end{align} \]
If \(d(\cdot, \cdot)\) is the Euclidean distance, \[W(C) =\sum_{k=1}^K n_k \sum_{C(i) = k} \lVert \mathbf{x}_i - m_k \rVert^2,\]
where \(m_k = (\bar{x}_{1k}, \dots, \bar{x}_{pk})\) is the mean vector of \(k\)th cluster.
Clustering Mathematical Formulation
- This is equivalent to maximizing the between cluster distance
\[B(C) = \frac{1}{2}\sum_{k=1}^K\sum_{(i, i'): C(i)=k}\sum_{, C(i')\ne k} d(\mathbf{x}_i, \mathbf{x}_{i'})\]
- The total distance is
\[T = \frac{1}{2}\sum_{i=1}^n \sum_{i'=1}^nd(\mathbf{x}_i, \mathbf{x}_{i'}) = W(C) + B(C)\]
\[\min_{C} W(C) \iff \max_{C} B(C)\]
Source: ISL Figure 12.8
iris Data
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
K-Means on iris
factoextra
Choose K: Total Withing Sum of Squares
Choose K: Average Silhouette Method
Choose K: Gap Statistics
Mixture of Gaussians
\(p\left(\mathbf{x}_i\right) = (0.4) N(\boldsymbol \mu_1, \boldsymbol \Sigma_1) + (0.6)N(\boldsymbol \mu_2, \boldsymbol \Sigma_2)\), \(\boldsymbol \mu_1 = (1, -1)\); \(\boldsymbol \mu_2 = (-1.5, 1.5)\), \(\boldsymbol \Sigma_1 = \begin{bmatrix} 1 & 0.5 \\ 0.5 & 1 \end{bmatrix}\); \(\boldsymbol \Sigma_2 = \begin{bmatrix} 1 & -0.9 \\ -0.9 & 1 \end{bmatrix}\)
mclust
Other Topics
- Hierarchical Clustering
- Spectral Clustering
- Dirichlet Process Mixture Models
![]()