Artificial Neural Networks 🙌
MSSC 6250 Statistical Machine Learning
Neural Networks
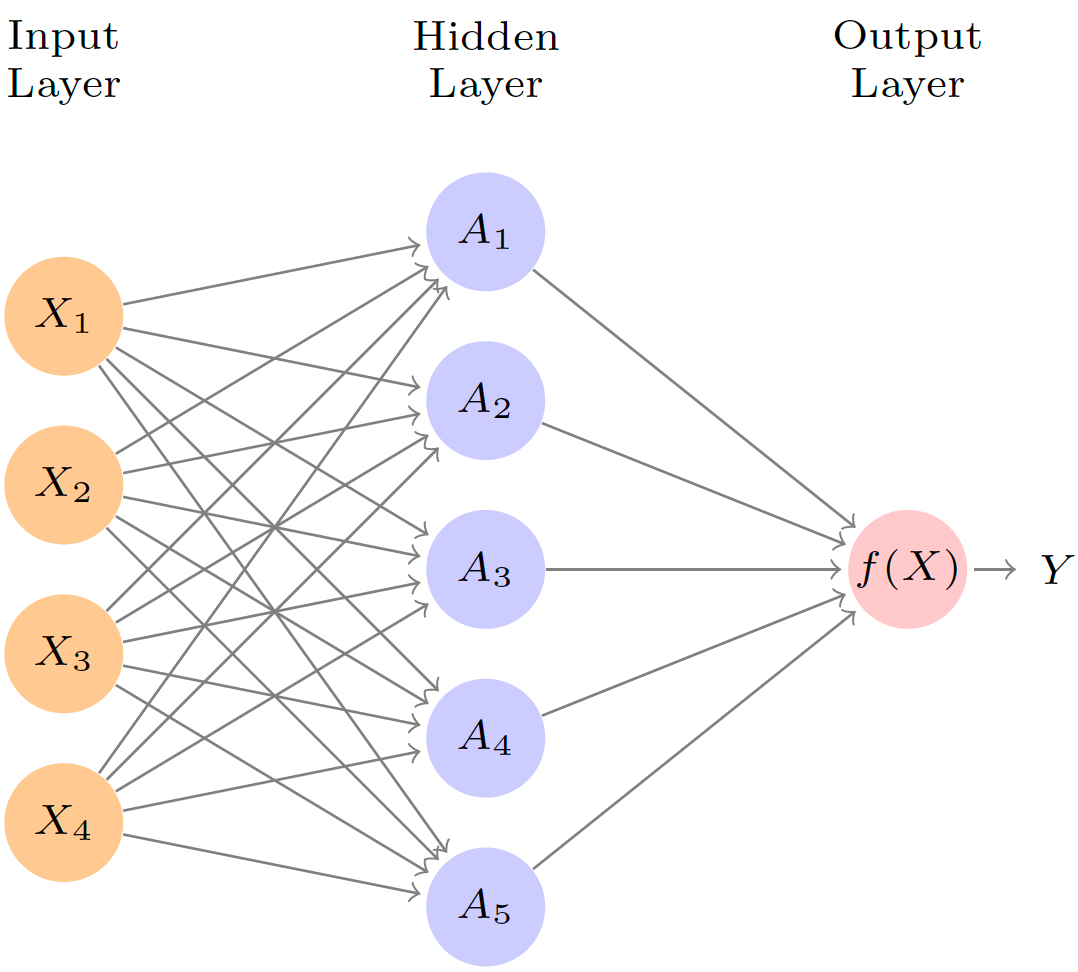
- An (artifical) neural network is a machine learning model inspired by the biological neural networks that constitute animal brains.


Deep Learning
A neural network takes an input vector of \(p\) variables \(X = (X_1, X_2, \dots, X_p)\) and builds a nonlinear function \(f(X)\) to predict the response \(Y\).
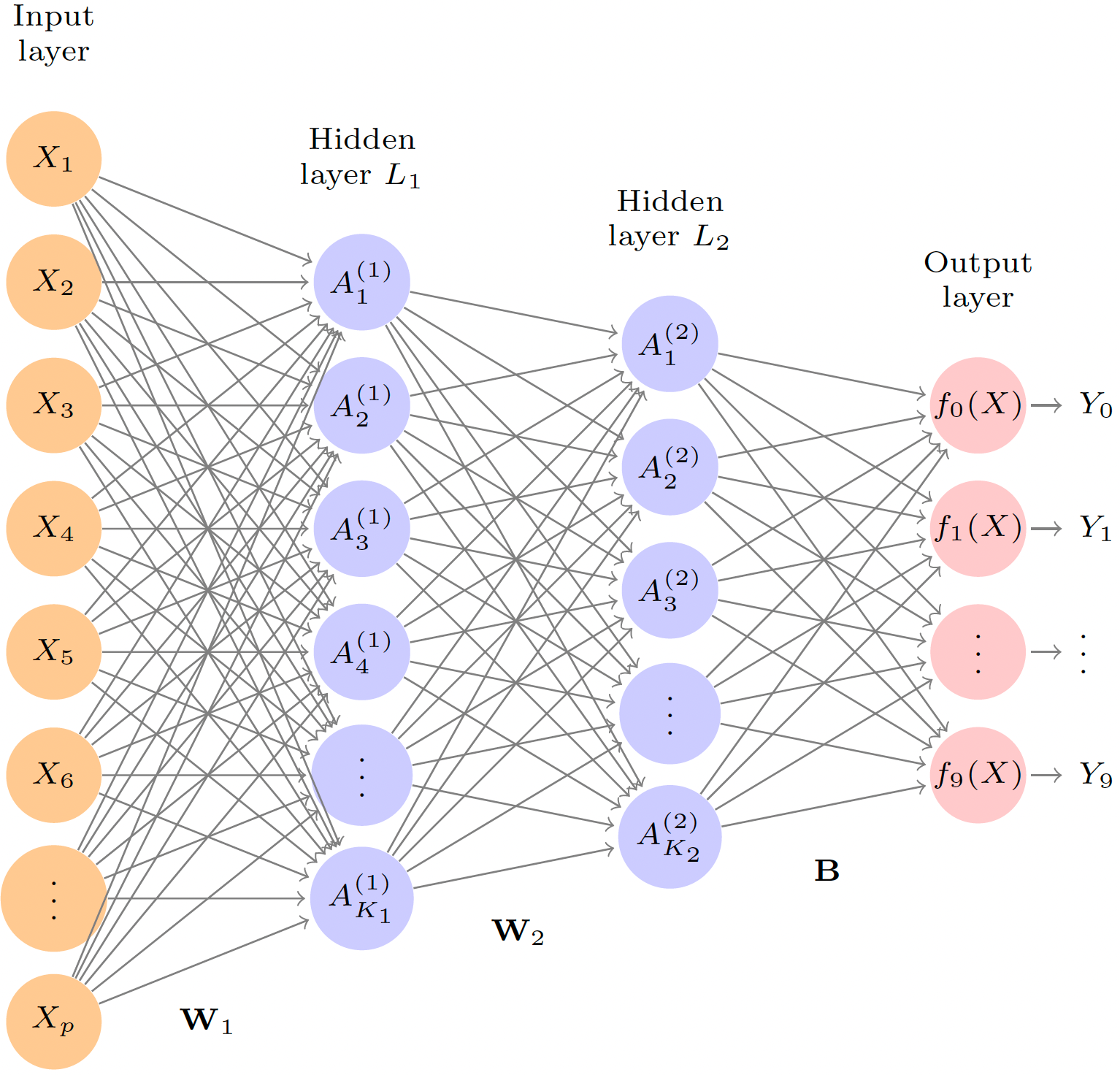
A neural network with several hidden layers is called a deep neural network, or deep learning.
Source: ISL Ch 10

Source: http://brainstormingbox.org/a-beginners-guide-to-neural-networks/

Fitting Neural Networks
\[\min_{\boldsymbol \beta, \{\mathbf{w}\}_1^K} \frac{1}{2}\sum_{i=1}^n\left(y_i - f(x_i) \right)^2,\] where \[f(x_i) = \beta_0 + \sum_{k=1}^K\beta_Kg\left( w_{k0} + \sum_{j=1}^pw_{kj}x_{xj}\right).\]
- This problem is difficult because the objective is non-convex: there are multiple solutions.
Other Topics
Stochastic Gradient Descent
Dropout Learning
Convolutional Neural Network (Spatial modeling)
Recurrent Neural Network (Temporal modeling)
Bayesian Deep Learning
![]()